
Lien Github: Human activity recognition
1. Introduction:
Le but de notre projet est de créer un système de recommandation intelligente pour les habitants dans une maison. Le système analyse et inter- prète les données des capteurs placés dans la maison et les combine avec des informations supplémentaires à l’extérieur (la météo,…) afin de proposer à l’utilisateur des suggestions pour améliorer leur vie quotidienne.
Le système comprend 2 parties :
- “Rule-based system”:
C’est un système de recommandation “classique” qui se base sur des règles prédéfinies du type “Si…, alors…,sinon…”.
Exemple : si la température à l’extérieur est supérieure de 25oC et il ne pleut pas et les fênetres sont fermées, alors le système demande à l’utilisateur s’il veux les ouvrir.Comme on peut constater facilement, ce système peut vite devenir très lourd à implémenter d’autant plus que c’est impossible de lister tous les scénarios dans la vie quotidienne. Pourtant, on a toujours l’intérêt à l’incorporer pour certaines situations spécifiques où des protocoles ou des processus sont fixés (l’incendie,…).
- “Machine learning system”:
Le coeur du programme. On utilise les algorithmes d’apprentissage automatique pour comprendre et apprendre les comportements de l’utilisateur et pour lui aider dans sa vie quotidienne. 2 types de messages seront envoyés par le système :
— “Prompting system”
Visé surtout pour les personnes âgées ou les personnes ayant des problèmes avec la mémoire, le système apprend leurs activités et leurs habitudes quotidiennes et leur envoie un message (sms,…) pour rappeler au cas où elles ont oublié à faire un tâche important. Les plus grandes contraintes techniques ici sont : la reconnais- sance des activités et la classification des tâches dans 2 catégories “important” et “pas important”. La deuxième contrainte est impor- tante parce que si le système envoie des messages à l’utilisateur chaque 5 minutes, il va poser une surcharge cognitive sur l’utili- sateur.— “Recommendation system”
En analysant les données dans la maison et en combinant avec des informations extérieure, le système peut donner à l’utilisateur des conseils pour améliorer leur vie. Il peut aussi détecter des anomalies dans la maison (vol, incendie, crise cardiaque,…).
Pour réaliser un tel système de recommandation, l’étape cruciale est de développer un système de reconnaissance des activités en basant sur les don- nées des capteurs. Dans la partie suivante, on va discuter les 3 approches que l’on a utilisé pour faire la reconnaissance : le modèle de Markov caché, l’algorithme k plus proche voisin et le réseau de neurones artificiels.
2. Reconnaissance des activités:
2.1 Jeu de données:
Notre projet est inspiré par l’article “Accurate Activity Recognition in a Home Setting” de Tim van Kasteren, Athanasios Noulas, Gwenn Englebienne et Ben Krose. On a utilisé leurs jeux de données pour tester les algorithmes.
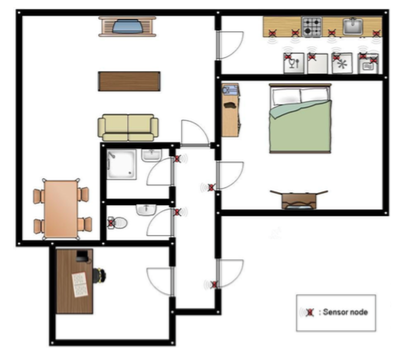
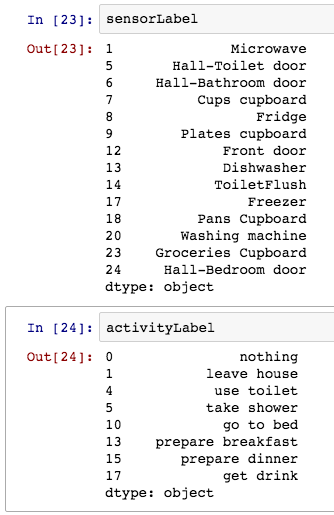
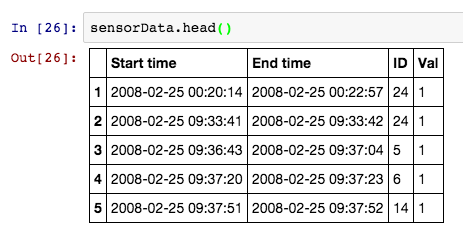
Il comprend 14 capteurs qui collectent des données de 8 activités pendant 28 jours, ce qui donne 2120 évènements de capteur et 245 évènements d’activité correspondants. Chaque évènement de capteur a 4 champs : Date de début, Date de fin, ID de l’activité et une variable qui indique l’activation du capteur.
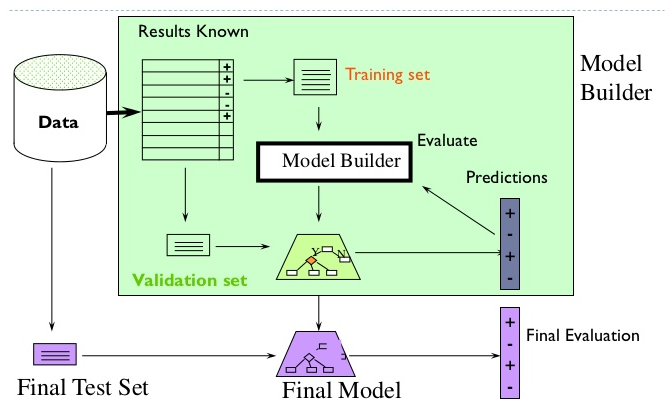
Pour éviter tous les bias et les faux positifs, on applique la méthode de cross-validation pour tester et valider les modèles. Le jeu de données a été partagés en 3 parties : training set, validation set, testing set. On utilise le training set pour l’apprentissage du modèle, après on utilise la validation set pour calibrer et régler les paramètres du modèle. Enfin, on teste le modèle sur le testing set pour trouver le taux d’erreur.
2.2 Chaine de Markov caché:
Modéliser les activités par une chaine de Markov caché est la méthode la plus classique. Les modèles de Markov caché sont beaucoup utilisés pour re- présenter des séquences d’observations (dans notre cas ce sont les données des capteurs). Grâce à ces modèles on peut construire une séquence de l’activité qui correspond le mieux aux données trouvés.
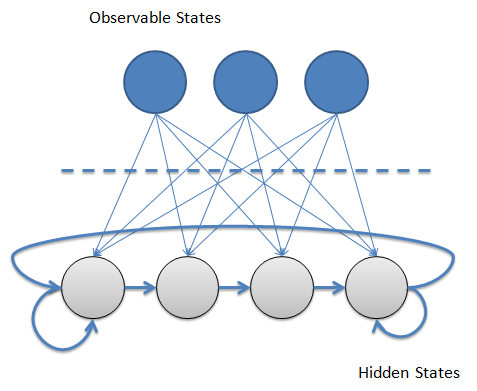
Il existe 2 étapes principales :
— Chercher les paramètres du modèle de Markov caché en calculant la fréquence des observations, des transitions,…
— Utiliser les algorithmes de Viterbi pour trouver la séquence d’activités la plus probable.
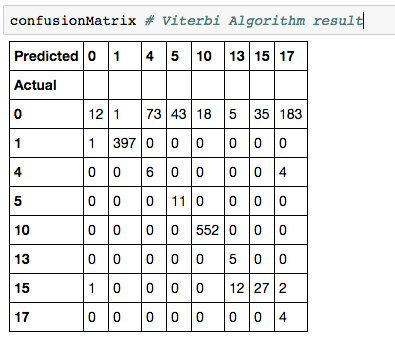
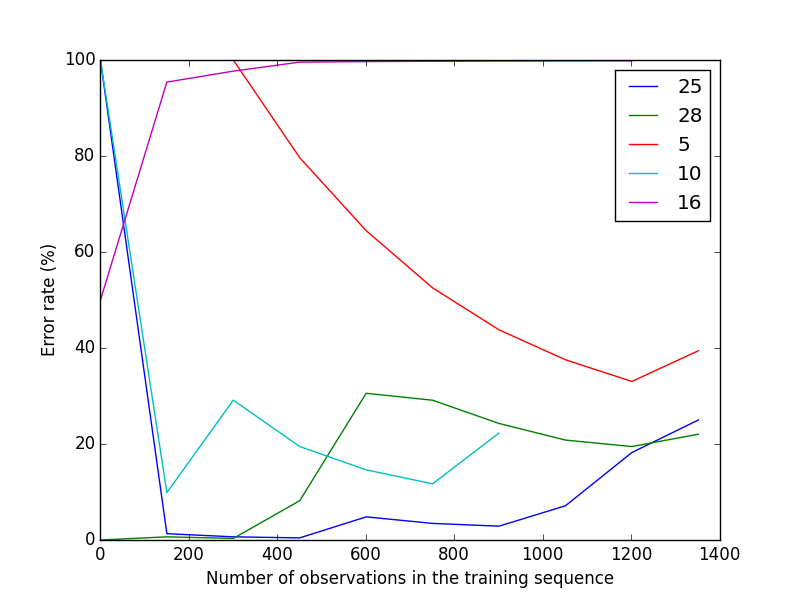
On a trouvé un taux d’erreur de 30%, ce qui n’est pas trop loin les résul- tats dans l’article (21%). Pourtant, le problème avec cet approche est que le modèle n’est pas stable. En obervant les figures ci-dessus, on peut remarque que les résultats varient beaucoup entre les différents jours. En plus, la ma- trice de confusion montre un faux positif significant liant à l’état 0 (nothing). Le problème vient du jeu de données, ou plus concrètement la façon dont on collecte les données : il faut rappeler que les capteurs étaient activés 24/24 pendant 28 jours, et donc la majorité du temps ils étaient à l’état “idle” – pas d’activité. Par conséquent, dans notre jeu de données, on a une très grande quantité de l’état 0 (nothing), ce qui rend les calculs biasés vers cet état.
2.3 k-Nearest Neighbors:
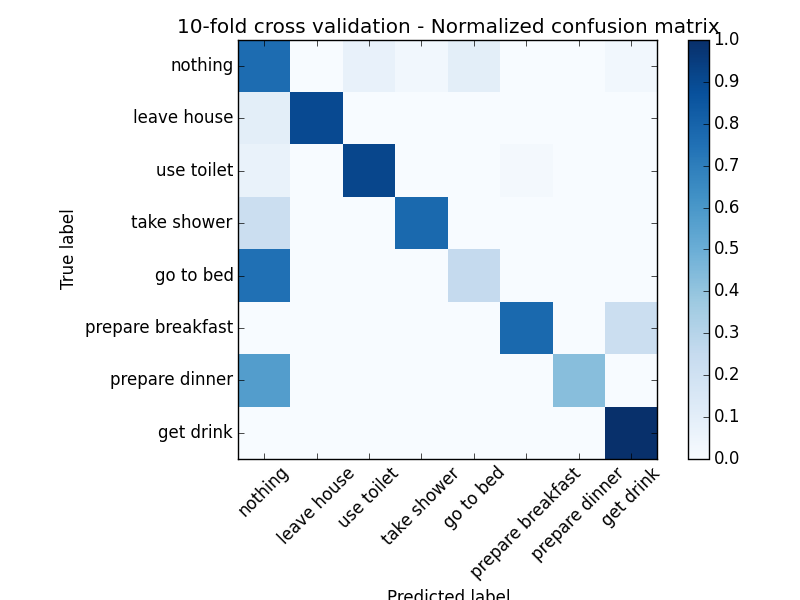
Le kNN est l’algorithme le plus simple pour faire la classification. On a utilisé le kNN avec la distance Mahalanobis et on a trouvé un taux d’erreur de 20%. Pourtant, l’amélioration la plus importante par rapport au modèle de Markov caché est la répartition des erreurs. Il existe toujours un bias vers l’état 0 mais ici la situation est déja beaucoup moins grave, avec seulement 2 activités qui sont souvent mal classifiés (go to bed et prepare dinner).
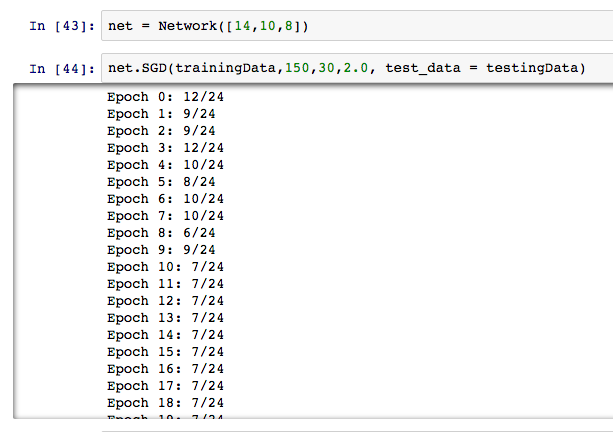
2.4 Artificial Neural Network:
Aujourd’hui, les réseaux de neurones artificiels apparaissent partout dans le monde de Machine Learning. On a tenté de le tester dans le cadre de notre projet. On a implémenté un réseau simple de type rétropropagation du gradient avec la fonction sigmoïde et 1 couche caché. Le nombre des neurones dans les 3 couches (entré, caché, sortie) est successivment 14 (le nombre de capteurs), 10 et 8 (le nombre de types d’activité). Les résultats trouvés pour le moment ne sont pas prometteurs. On a déja testé notre algorithme sur un autre jeu de données et on a reçu des bonnes résultats, ce qui montre que notre implémentation n’a pas d’erreurs. On pense que le problèmes se pose sur 2 points :
— Le choix des hyper-paramètres : nombre de neurones, taux d’appren- tissage de l’algorithme du gradient. Comme c’est la première fois que l’on utilise un réseau neurone, on n’est pas sur comment on peux bien régler tous ces paramètres.
— Le jeux de donnée n’est pas assez large pour un réseau de neurone.
2.5 Amélioration:
Pour l’instant on a un taux d’erreur de 20-30%, ce qui est acceptable.
Une idée pour améliorer les résultats du modèle de Markov caché est d’utiliser 2 modèles : l’un pour le matin et l’autre pour le soir. Cette sug- gestion vient du fait que notre algorithme dépend beaucoup de l’ordre des activités, ce qui est en même temps le point fort et le point faible de HMM. Les routines du matine et du soir sont très différents, et en les séparant on aura 2 modèles avec moins de bruits et plus de précision.
Pour le kNN, on peut utiliser 2 modèles aussi. L’avantage du modèle de Markov caché est qu’il permet de modéliser l’ordre des activités. On perd ces informations avec le kNN. Pourtant, on peut les incorporer en présentant un deuxième modèle qui va modéliser la probabilité que l’activité X est suivie par l’activité Y.
