There are many ways to classify machine learning algorithms: supervised/unsupervised, regression/classification,… . For myself, I prefer to distinguish between Discriminative model and Generative model. In this article, I will discuss the relationship between these 2 families, using Gaussian Discriminant Analysis and Logistic Regression as example.
Quick review: Discriminative methods model 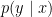

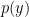

There are quite some reasons why discriminative models are more popular among machine learning practitioner: they are more flexible, more robust and less sensitive to incorrect modeling assumptions. Generative models, on the other hand, require us to define the distribution of our prior, which can be quite challenging for many situations. However, this is also their advantage: they have more “information” about the data than discriminative model, and thus can perform quite well with limited data if the assumption is correct.
In this article, I will demonstrate the point above by proving that Gaussian Discriminant Analysis (GDA) will eventually lead to Logistic Regression, and thus Logistic Regression is more “general”.
For binary classification, GDA assumes that the prior follows a Bernoulli distribution and the likelihood follows a multivariate Gaussian distribution:
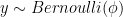


Let’s write down their mathematical formula:
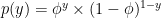
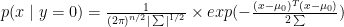

As mentioned above, the discriminative model (here is the logistic regression) try to find

which is the sigmoid function of logistic regression, where 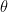
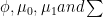
Ok let’s roll up our sleeves and do some maths:



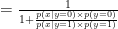
This equation seems very much like what we are look for, let’s take a closer look at the fraction 


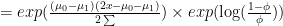


![= exp[ (\log(\frac{1-\phi}{\phi}) - \frac{\mu_0^2 + \mu_1^2}{2\sum}) \times x_0 + \frac{\mu_0 - \mu_1}{\sum} \times x ]](https://s0.wp.com/latex.php?latex=%3D+exp%5B+%28%5Clog%28%5Cfrac%7B1-%5Cphi%7D%7B%5Cphi%7D%29+-+%5Cfrac%7B%5Cmu_0%5E2+%2B+%5Cmu_1%5E2%7D%7B2%5Csum%7D%29+%5Ctimes+x_0+%2B+%5Cfrac%7B%5Cmu_0+-+%5Cmu_1%7D%7B%5Csum%7D+%5Ctimes+x+%5D&bg=ffffff&fg=000000&s=0&c=20201002)
In the last equation, we add 

![\frac{1}{1 + \frac{p(x \mid y=0) \times p(y=0)}{p(x \mid y=1) \times p(y=1)}} = \frac{1}{1 +exp[ (\log(\frac{1-\phi}{\phi}) - \frac{\mu_0^2 + \mu_1^2}{2\sum}) \times x_0 + \frac{\mu_0 - \mu_1}{\sum} \times x ] }](https://s0.wp.com/latex.php?latex=%5Cfrac%7B1%7D%7B1+%2B+%5Cfrac%7Bp%28x+%5Cmid+y%3D0%29+%5Ctimes+p%28y%3D0%29%7D%7Bp%28x+%5Cmid+y%3D1%29+%5Ctimes+p%28y%3D1%29%7D%7D%C2%A0%3D+%5Cfrac%7B1%7D%7B1+%2Bexp%5B+%28%5Clog%28%5Cfrac%7B1-%5Cphi%7D%7B%5Cphi%7D%29+-+%5Cfrac%7B%5Cmu_0%5E2+%2B+%5Cmu_1%5E2%7D%7B2%5Csum%7D%29+%5Ctimes+x_0+%2B+%5Cfrac%7B%5Cmu_0+-+%5Cmu_1%7D%7B%5Csum%7D+%5Ctimes+x+%5D+%7D&bg=ffffff&fg=000000&s=0&c=20201002)
And there it is, we just proved that the result of a Gaussian Discriminant Analysis is indeed a Logistic Regression, our vector 
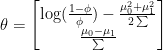
The converse, is not true though: 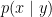
(The problem of GDA, or generative model, can be solved with a class of Bayesian Machine Learning that uses Markov Chain Monte Carlo to sample data from their posterior distribution. This is a very exciting method that I’m really into, so I will save it for a future post.)
